ChatGPT wrote a Static Site Generator
…with my help. Long story short: I suck at bash scripting.
Seriously, I write code for almost 20 years but I never had to learn bash. Judge me!
I was able to find my way around, with long hours of Google, but I had never written a non-trivial script. Also, I got pretty bored trying to read Hugo and Jekyll docs, and I wanted a dead simple website.
So I asked ChatGPT (Jan 9 2023 version) to build a static site generator in Bash.
Here is the end result, after some iterations:
#!/usr/bin/env bash
if [[ $1 == "-h" || $1 == "--help" ]]; then
echo "Usage: ./script.sh layout.html input_dir output_dir"
echo
echo "Convert all Markdown files from input_dir to HTML and apply layout.html."
echo "Replace {{ partial_filename }} in the generated output by the contents the partial file."
echo "Support subdirectories."
echo "Non-Markdown files in input_dir are copied to output_dir."
exit 0
fi
layout=$1
input_dir=$2
output_dir=$3
# Show help if number of params are incorrect, or if they don't exist
[ $# != 3 ] && { sh $0 -h; exit 1; }
[[ -f "$layout" ]] || { echo "Error: Layout does not exist"; exit 1; }
[[ -d "$input_dir" ]] || { echo "Error: Input directory does not exist"; exit 1; }
[[ -d "$output_dir" ]] || { echo "Error: Output directory does not exist"; exit 1; }
# Check if pandoc is installed
hash pandoc 2>/dev/null || { echo >&2 "Error: pandoc is not installed. Please install it to use this script."; exit 1; }
# Iterate through all files in input directory or its subdirectories
find "$input_dir" -type f | while read file; do
# Get the relative path to the file: remove input_dir from prefix
relative_path=${file#$input_dir/}
# Ensure the same directory structure exists in output directory
file_dir=$(dirname "$output_dir/$relative_path")
[ -d "$file_dir" ] || mkdir -p "$file_dir"
if [[ "$file" == *.md ]]; then
# Convert Markdown to HTML and apply layout
pandoc --highlight-style tango --quiet "$file" --template "$layout" -o "$output_dir/${relative_path%.md}.html"
else
# Copy non-Markdown files to the output directory
cp "$file" "$output_dir/$relative_path"
fi
done
# Iterate through all HTML files in output directory or its subdirectories
find $output_dir -name '*.html' | while read file; do
tmp_file="${file}.tmp"
# Iterate through each line of the input file
while read line; do
# Check if the line contains the string {{ file_name }}, also capture its prefix and suffix
if [[ $line =~ ^([^\{\{]*)\{\{([^\}]*)\}\}(.*)$ ]]; then
# Get file_name from regex, strip whitespaces and prefix with output_dir
file_name=$output_dir/$(echo ${BASH_REMATCH[2]} | tr -d " ")
# Substitute by the contents of the file, keeping prefix and suffix
[ -f $file_name ] && line="${BASH_REMATCH[1]}$(cat $file_name)${BASH_REMATCH[3]}"
fi
# Append the line to the output file
printf "%s\n" "$line" >> $tmp_file
done < $file
mv $tmp_file $file
doneWarning: so far only tested in OSX 12.5.1. Open an issue in GitHub if you find problems.
Here is the list of features:
- Markdown pages with custom HTML layout
- Standalone HTML pages
- Supports subdirectories
- Syntax highlight for code blocks with
tangocolors - HTML partials with
{{ partial_filename.html }} - ZERO setup
- 1 dependency (pandoc)
- ~60 lines with help section and well commented code
You can check this GitHub repository to see how I used this simple Static Site Generator to build the website you are reading.
Useful tips
- Use entr to rebuild the website when you make changes to HTML and Markdown files:
$ find . -name '*.html' -o -name '*.md' -o -name '*.sh' | entr ./script.sh layout.html src docsStart a webserver to have an environment closer to production:
With this you can use HTTP features of javascript to send HTTP requests. You have better support for links, for example you can write tosrc="/index.html"on any subdirectory link to refer to the root/folder of our server, which is like production. Finally, it handles assets with the proper content-type. OSX comes with Ruby, which lets you simply runcd docs/ && ruby -run -ehttpd . -p8000to have a server onlocalhost:8000. Or you can choose any other option from this list.Deploy your website to GitHub
Clone this repository to your website directory. Modify thesrc/markdown and HTML files. Create a repository on GitHub then run this on the directory of your website, changingusername/repository_nameaccording to what you set on GitHub. Finally, you need to configure GitHub pages on you repositorySettings > Pagesto serve from main branch, from thedocs/directory.
# clone this code
$ git clone https://github.com/alexandremcosta/alexandremcosta.github.io.git website/
# make changes to src/ directory...
# generate the website in the docs/ directory
$ sh script.sh src/layout.html src/ docs/
# publish
$ git add .
$ git commit -m "my custom editions"
$ git remote set-url origin git@github.com:username/repository_name.git
$ git push -u origin main
And voilá! You have a blog online, just like mine, on
https://username.github.io/repository_name. To remove the
/repository_name part, you have to call your repository
username.github.io.
A bit more of context
Of course ChatGPT didn’t come with this code ready on the first iteration. It was more like:
PROMPT: write a minimal static site generator in bash script with support to markdown pages and partial templates
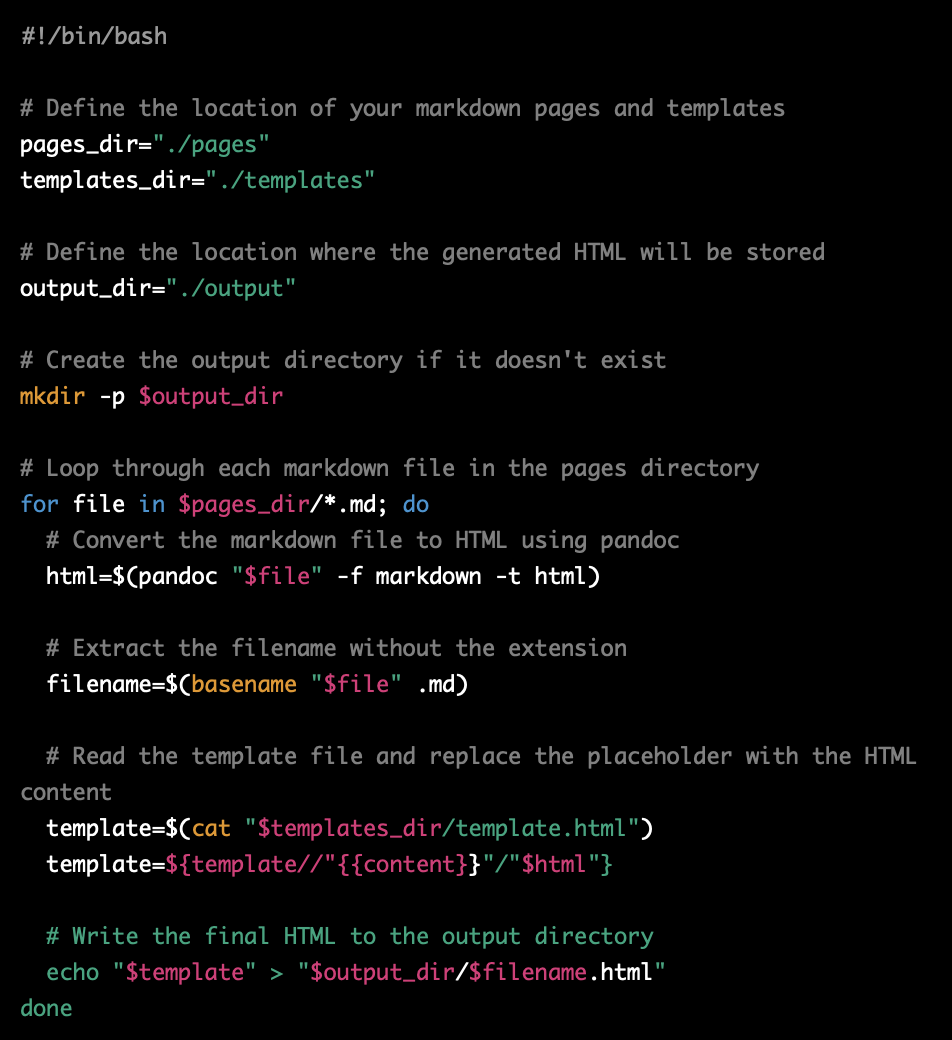
PROMPT: change this script so that pandoc supplies the html layout itself. Also add support for partial templates, for example for any generated html file contains {{ filename }} or {{ another_filenane }} it substitutes this string by the contents of the respective file
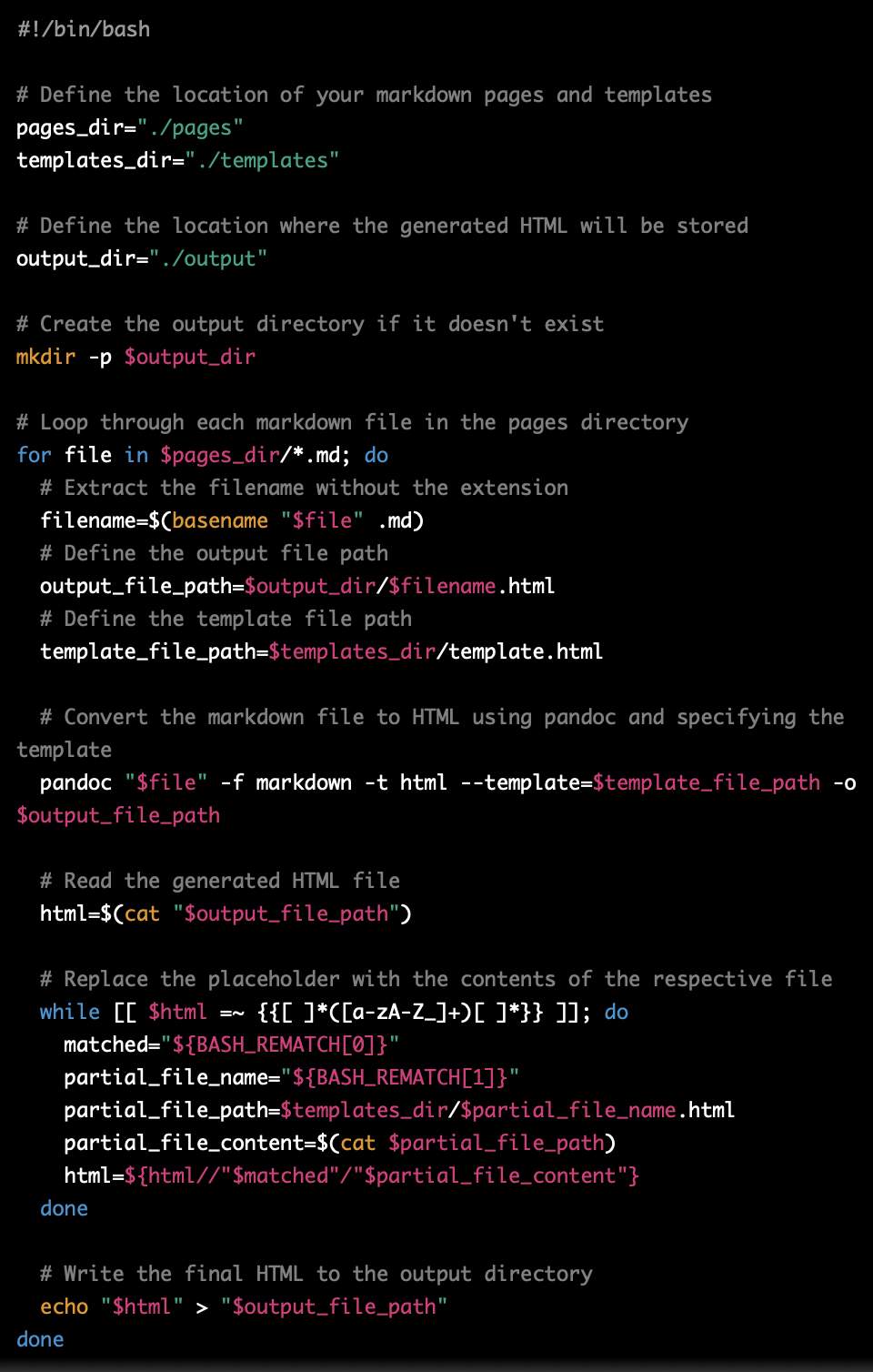
Then, I kept testing the result on my machine, fixing ChatGPT errors
and iterating with the prompt until we got the final result. Finally I
asked it to write the --help flags, improve the comments
and reduce some lines that were too verbose.
I knew it was possible to generate a site with Pandoc, but I could never write anything polished like this by myself. Thanks ChatGPT.
Drop me an email if you find this cool or if it doesn’t work for you! Or open an Issue on this website repository if you have any comments.